Contents
- Introduction
- Overview
- Data validation process
- Framework core components
- Key Features
- Validation rule severity levels
- Example validation rules introduction
- Use Cases
- Benefits
- Prerequisites
- Limitations
- Technologies used
- Summary
- Related Topics
1. Introduction
Data quality is generally considered as one of the four pillars of good data management. To ensure data quality, a variety of measures are usually put in place in database solutions.
The simplest data quality measures are obviously easy to implement. However, what if we were to implement complex data validation rules to ensure data quality? Depending upon the complexity of the rules, we may need to build custom data validation process.
This is where the data validation framework, as discussed in this article can play a helpful role.
The purpose of this article is to present a simple SQL data validation framework using which you can build a data validation process and execute it as part of ETL process or as a standalone process, to validate data against complex data validation rules as well as simple rules.
This article was the first of the three-part series on SQL data validation framework.
2. Overview
Data validation framework, as described in this article can be useful in three broad scenarios as below, to build data validation processes that validate data against complex as well as simple validation rules.
- Data migration
- Data extracts for external agencies
- Data warehouse loading
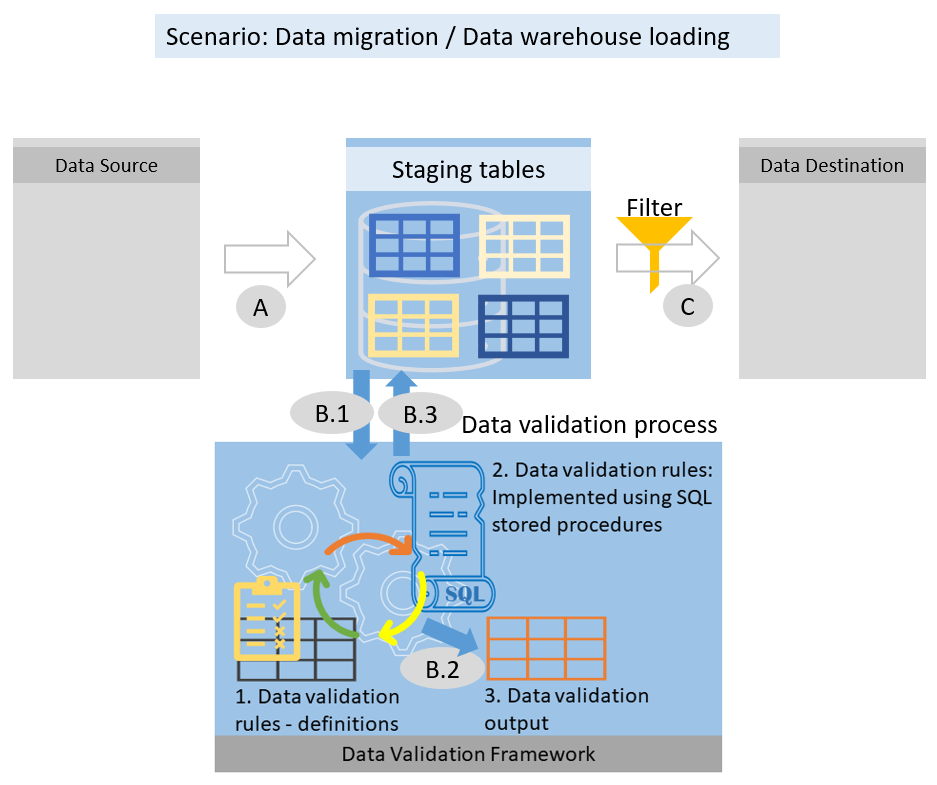
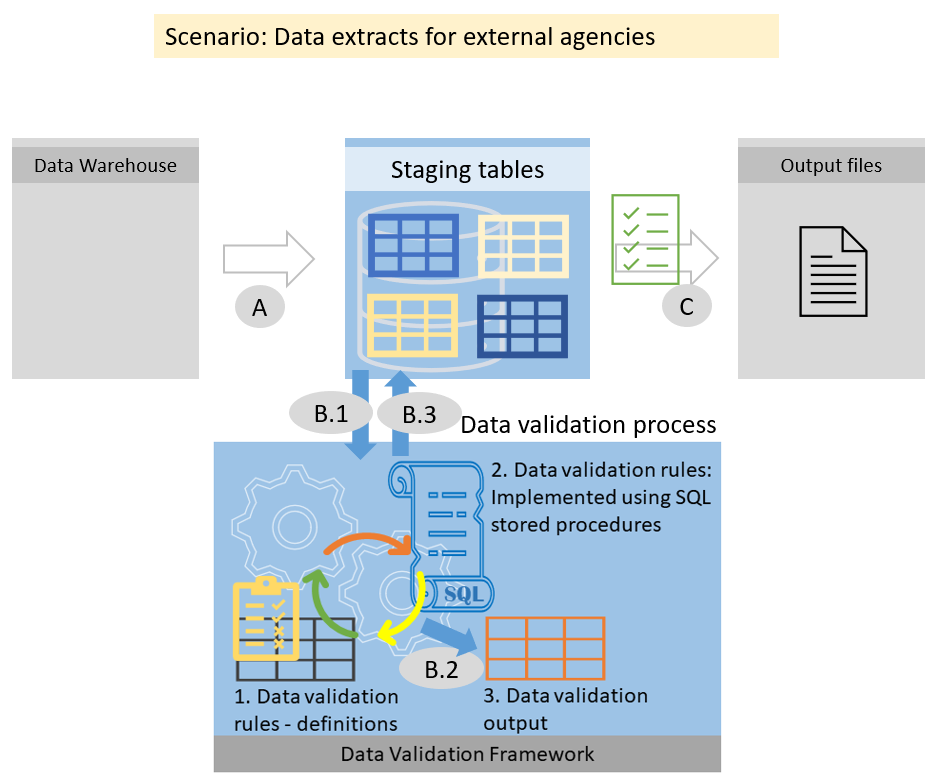
3. Data validation process – where does it fit in?
Referring to the figures 1.1 and 1.2 as above:
- Process A: Loads data from source systems to staging
- Process B: Data validation process
- B.1 – applies data validation rules on staging data
- B.2 – writes row IDs of rows that broke validation rules to validation output table
- B.3 – marks rows in staging tables as invalid if they broke critical validation rules
- Process C: Loads data from staging to destination, optionally filtering out invalid rows
4. Data validation framework core components
The data validation framework at its core consists of two tables and a set of stored procedures along with a few other supporting tables and utility stored procedures:
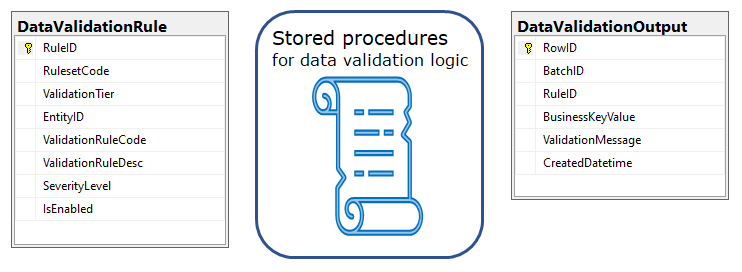
- DataValidationRule table – contains data validation rule definitions
- A set of SQL stored procedures – implements data validation rules
- DataValidationOutput table – stores data validation output
5. Key Features
- Almost any complex data validation rule can be implemented as long as the rule itself can be written in SQL
- Ability to segment data validation rules into several tiers of dependency as necessary
- Ability to assign to each data validation rule a severity level of E (Error) or Warning (W)
- Ability to switch severity level of a validation rule between E and W without any programming changes
- Ability to enable or disable any validation rule without the need to change source code
6. Validation rule severity levels
The validation framework gives us the ability to specify a rule severity level as either E (Error) or W (Warning).
Severity level E (Error): if a validation rule is assigned a severity level of E (Error), then those data rows that broke the rule would be marked as invalid in staging table and optionally can be excluded from loading to destination table, aside from logging the fact to validation output table.
Severity level W (Warning): if a validation rule is of severity level W (Warning), then identifiers (IDs) of those rows that broke the rule are logged to validation output table. But the validity status of rows in staging table remain unaffected, unlike in case of severity level E.
7. Example data validation rules – introduction
To demonstrate the framework, let us consider a fictitious and simple data model of a data store with made up data validation rules:
Say, we have three entities in our data store: Customer, Account and Address.
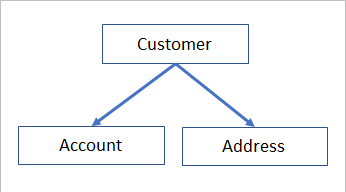
Example “Babushka“ rule:
Put simply, imagining a data migration scenario, the example business rule was that: load data of a customer and its linked accounts and addresses to destination, ONLY when all the related data of a customer have not broken any critical business rules. Additionally, a customer must have at least one account and one address.
As you might have already realised it, this example business rule is a kind of a Babushka type rule, where in many validation rules were contained in one big business rule.
The same business rule when broken down into parts for implementation and segmented into validation tiers and arranged into sequential order of dependency for execution, could look as below:
| Validation rule tier | Example data validation rules |
| Tier 0 | You may want to start with validating individual entities by applying any basic data integrity rules as appropriate – such as validating for mandatory NOT NULL fields, duplicate business keys etc. |
| Tier 1 | A customer must have at least one account and one address. If neither of these child entities exist, then the customer shouldn’t be loaded to destination. Account and Address must have a parent (existing customer). They cannot be orphans |
| Tier 2 | If a customer has one or more invalid child records (account and address), then the customer shouldn’t be loaded to destination |
| Tier 3 | If the parent (customer) is invalid for whatsoever reasons, then its valid child entities (account and address) should also be invalidated so that orphan child records won’t be loaded to destination |
The implementation of these example validation rules will be covered in more detail in the next part of this three part article.
8. Use Cases
(i) In data migration
Picture this: You are migrating data from a source system into a destination SQL Server or similar RDBMS system. The structures of database tables and business rules at destination were different to those at source. Millions of records were to be migrated. Additionally, adopted migration strategy was to migrate data in smaller batches over a few months rather than as a ‘big-bang’ approach, to minimise impact to millions of customers.
Your business stakeholders wanted only the completely valid datasets to be migrated. What I mean by it is that migrate a customer only when all its linked entities such as account, address etc. too were valid.
Realistically, not every record being migrated may satisfy every critical business rule of the destination. Some records might break business rules. Sometimes, the same record could be breaking multiple business rules.
The business also wanted to know the reasons for rejections as soon as possible, with as much insight into the reasons for rejection as possible, so that data cleansing of such offending data can be initiated in the source system sooner than later.
In such situations, wouldn’t it be nice if you could put in place a data validation process that marks offending records of data as invalid and excludes such bad data and its linked entity records from loading to destination? Also, wouldn’t it be nice, if the data validation process could also tell you as to what are all the different validation rules that a given invalid record broke, so that corrective measures could be taken in one-go rather than in a piece-meal manner?
(ii) Data extracts for external agencies (e.g. regulatory authorities)
While your database was designed to cater for the business rules of your own organisation, you might be required to extract data from your database for external agencies including regulatory authorities. The external agency may have its own data validation rules while uploading your extract into their system. In such cases, wouldn’t it be nice if you could validate the extracted data from your database by applying all the data validation rules of the external agency and know beforehand the potential data issues, well before it was loaded to destination?
(iii) In data warehouse loading
While a data warehouse gets data from multiple source systems, it is quite possible that the source data may not necessarily satisfy all the data validation rules of the destination. By putting in place a data validation process at a stage before loading to the destination, you get to know all the different data validation rules that a given record broke. This comprehensive information about the broken business rules could help understand and resolve the underlying data issue relatively quickly.
9. Benefits
By building a data validation process following the data validation framework presented in this article, you could get the following benefits:
(i) Easy to know all the different rules that a given row had broken
The example screenshot as below tells us that the CustomerID: C001 had broken five different data validation rules.
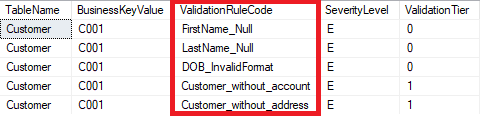
Given that a row of data could be breaking multiple validation rules, this kind of output can give a comprehensive view of the underlying data issues in a given row, so that holistic corrective action can be taken rather than in a piecemeal manner.
An exception to this benefit is when the business key itself was absent (NULL). When its business key was absent, the framework doesn’t support applying remainder of the rules on such record.
(ii) Easy to identify all the rows that broke a given validation rule
The example screenshot as below tells us that data validation rule “DOB_FutureDate” was broken by three customer records: C003, C004, C005

Acknowledgement: Rockford Lhotka’s textbook – Visual Basic 6 Business Objects (a hardcopy of which I still have since 1999) – was the source of inspiration to me, in building this data validation framework in such a way that it would validate data against every applicable validation rule rather than discontinue validating a record, the moment it breaks the first rule.
(iii) You can take staging data for a ‘test-drive’ to assess data quality before actually loading data to destination, by running the validation process as a standalone process.
(iv) Easy to export output of data validation process – to Excel, along with various rules that an offending record had broken
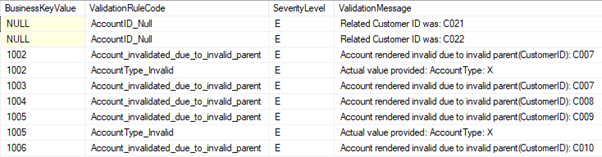
Alternatively, XML can be used to generate more detailed output including a snapshot of values in each column of an affected row.
(v) Easy to export data validation rules – to Excel for periodic review by data stewards or similar
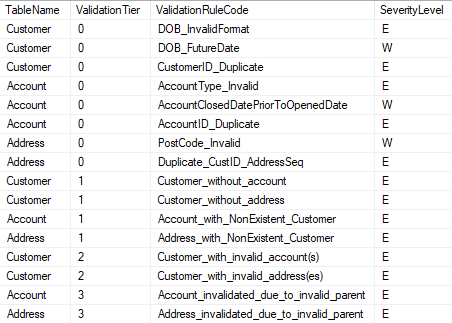
(vi) Can be used as part of regular ETL processes or as a standalone data validation process to periodically assess data quality
10. Prerequisites
- The data will need to be staged in staging tables for validation before loading it to destination.
- A mostly unique business key or a surrogate key must be present in each staging table that’s going to be validated. A business key can be a single column or a composite key.
- ‘IsValid’ column or equivalent in each staging table is expected to be present. The IsValid column is marked as 0 (false) during validation process, if a given row broke any validation rules that have a severity level of E (ERROR).
11. Limitations
- Data cleansing isn’t part of this data validation framework. It identifies and marks invalid rows. However, it doesn’t cleanse the data by itself. So, separate corrective action will be required to address the data issues.
- If you choose to exclude invalid rows (IsValid = false), while loading data from staging to destination, then the SQL queries that retrieve data from staging tables would require modifications to filter out invalid rows.
- In case of data warehouse scenarios, if you choose to automatically exclude invalid rows (IsValid = false), be mindful that further action would be required to resolve the data quality issues of the excluded rows. Otherwise, they could be missed out from making it to destination for ever. To mitigate such risk, one option is to let them be loaded to destination despite being invalid. At the same time, you would still have the validation output in your hand for corrective action. Another option is to build automated re-process to re-fetch from the source the data for the offending rows every time the ETL process is run, in anticipation of a data fix in source based on your validation output report.
12. Technologies used
Although the framework and the example validation process were built using T-SQL in SQL Server 2016, it can easily be adapted to work with other RDBMS platforms such as Oracle and DB2 etc.
13. Summary
The data validation framework as presented in this article can be used to build data validation processes. It can easily implement complex data validation rules as well as simple rules. And it is simple and easily extensible as the data validation rules grow or change with time. The inputs to this data validation process are the data in staging tables, data validation rules listed in a database table and the data validation rules itself that were implemented in SQL stored procedures. The validation results are written to validation output table, which identify offending rows of data and the rules that they broke. Separate action would be required to cleanse offending data.
Thank you for your interest in reading this article.
14. Related topics
This article was the 1st of the three-part series on SQL data validation framework. For other parts of this article including video presentations of the same, refer to the below links:
